A review of deep learning models for semantic segmentation
This article is intended as an history and reference on the evolution of deep learning architectures for semantic segmentation of images. I am an Engineer, not a researcher, so the focus will be on performance and practical implementation considerations, rather than scientific novelty.
Semantic segmentation is a natural step-up from the more common task of image classification, and involves labeling each pixel of the input image. In practice, this ends up looking like this:

The list below is mostly in chronological order, so that we can better follow the evolution of research in this field.
Fully Convolutional Networks for Image Segmentation (2016)
Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation.
This is easily the most important work in Deep Learning for image segmentation, as it introduced many important ideas:
- end-to-end learning of the upsampling algorithm,
- arbitrary input sizes thanks to the fully convolutional architecture,
- pretraining on classification tasks,
- skip connections for multi-scale inference.
The first concept to understand is that fully-connected layers can be replaced with convolutions whose filter size equals the layer input dimension. As explained in CS231n, this equivalence enables the network to efficiently "sweep" over arbitrarily sized images while producing an output image, rather than a single vector as in classification.
While the output from a fully convolutional network could in principle directly be used for segmentation, it is usually the case that most network architectures downsample heavily to reduce the computational load. The paper introduces two ways to increase the resolution of the output.
The first approach has to do with dilation, and we're going to discuss it alongside the next paper. The second is usually called deconvolution, even if the community has been arguing for years about the proper name (is it fractionally-strided convolution, backwards convolution, transposed convolution?) Whatever the name, the core idea is to "reverse" a convolution operation to increase, rather than decrease, the resolution of the output. Since the convolution kernels will be learned during training, this is an effective way to recover the local information that was lost in the encoding phase.
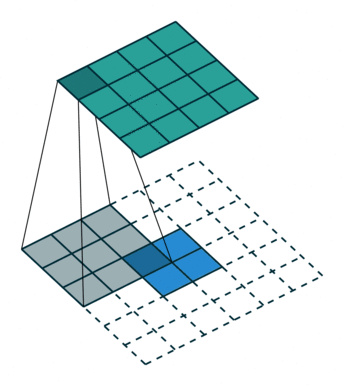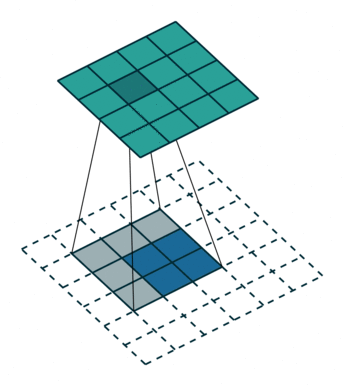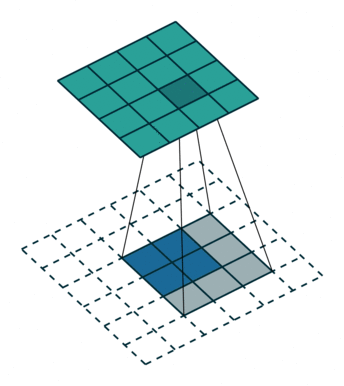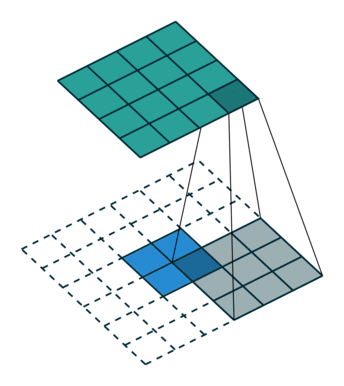
Finally, this paper introduces skip connections as a way of fusing information from different depths in the network, that correspond to different image scales. The authors find that these connections add a lot of detail.
DilatedNet (2016)
Yu, F., & Koltun, V. (2016). Multi-Scale Context Aggregation by Dilated Convolutions.
DilatedNet is a simple but powerful network that I enjoyed porting to Keras. The authors propose doing away with the "pyramidal" architecture carried over from classification tasks, and instead use dilated convolutions to avoid losing resolution altogether.
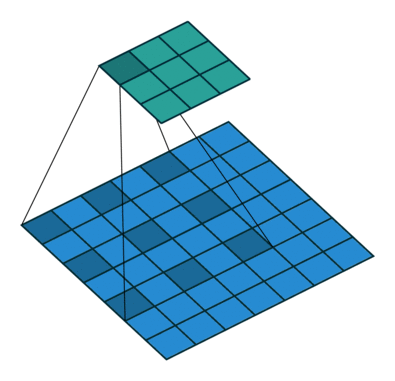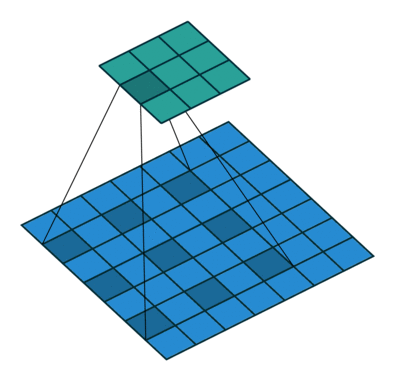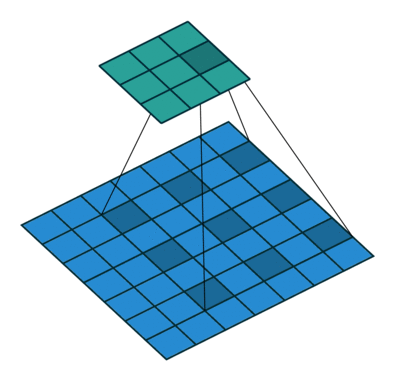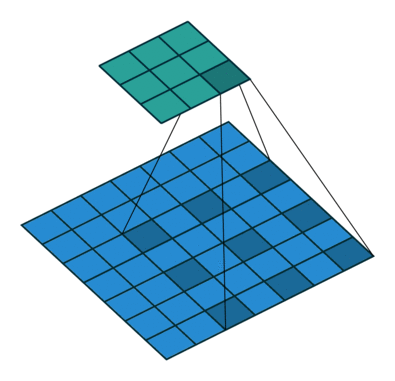
By using convolutional filters with "holes", the receptive field can grow exponentially while the number of parameters only grows linearly.
The frontend alone, based on VGG-16, outperforms DeepLab and FCN by replacing the last two pooling layers with dilated convolutions. Additionaly, the paper introduces a context module, a plug-and-play structure for multi-scale reasoning using a stack of dilated convolutions on a constant 21D feature map.
As reported in the appendix, this model also outperforms the state of the art in urban scene understanding benchmarks (CamVid, KITTI, and Cityscapes).
The One Hundred Layer Tiramisu (2016)
Jégou, S., Drozdzal, M., Vazquez, D., Romero, A., & Bengio, Y. (2016). The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation.
This very recent paper (Dec 2016) develops a DenseNet-based segmentation network, achieving state-of-the-art performance with 100x less parameters than DilatedNet or FCN. In DenseNet networks, each layer is directly connected to all other layers. While these connections were originally introduced to allow training very deep networks, they're also a very good fit for segmentation thanks to the feature reuse enabled by these connections.
The authors use transposed convolution for the upsampling path, with an additional trick to avoid excessive computational load. The attached benchmarks show that the FC-DenseNet performs a bit better than DilatedNet on the CamVid dataset, without pre-training.
Adversarial networks
Luc, P., Couprie, C., & Kuntzmann, L. J. (2016). Semantic Segmentation using Adversarial Networks.
Following the current excitement over the potential of Generative Adversarial Networks (GAN), the authors introduce an adversarial loss term to the standard segmentation FCN. The idea is that the discriminator would be able to use high-level information about the entire scene to assess the quality of the segmentation. In a sense, this acts as an high-order CRFs that's otherwise difficult to implement with conventional inference algorithms.
The segmentation side of the GAN was based on DilatedNet, and the results on Pascal VOC show a few percent points of improvement.
Mentions
U-net (2015)
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation.
Most of the networks we've seen operate either on ImageNet-style datasets (like Pascal VOC), or road scenes (like CamVid). U-Net is interesting because it applies an FCN architecture to biomedical images, and presents an hardcore augmentation workflow to make the most out of the limited data available in that field.
Segnet (2015)
Badrinarayanan, V., Kendall, A., & Cipolla, R. (2015). SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. Cvpr 2015.
While the ArXiv preprint came out at about the same time as the FCN paper, this CVPR 2015 version includes thorough comparisons with FCN. It contains an interesting discussion of different upsampling techniques, and discusses a modification to FCN's that can reduce inference memory 10x with a loss in accuracy.
Conclusions
Not unlike classification, a lot of manpower in segmentation has been spent in optimizing post-processing algorithms to squeeze out a few more percentage points in the benchmark. For this reason, I believe that a simple network like DilatedNet is currently the best suited for real-life implementation, and would be a good base to build custom post-processing pipelines. You can try out my Keras implementation.
All images are reproduced from the corresponding papers. Animations are from here.