Gradient Boosting in TensorFlow vs XGBoost
Tensorflow 1.4 was released a few weeks ago with an implementation of Gradient Boosting, called TensorFlow Boosted Trees (TFBT). Unfortunately, the paper does not have any benchmarks, so I ran some against XGBoost.
For many Kaggle-style data mining problems, XGBoost has been the go-to solution since its release in 2006. It's probably as close to an out-of-the-box machine learning algorithm as you can get today, as it gracefully handles un-normalized or missing data, while being accurate and fast to train.
The code to reproduce the results in this article is on GitHub.
The experiment
I wanted a decently sized dataset to test the scalability of the two solutions, so I picked the airlines dataset available here. It has around 120 million data points for all commercial flights within the USA from 1987 to 2008. The features include origin and destination airports, date and time of departure, arline, and flight distance. I set up a straightforward binary classification task that tries to predict whether a flight would be more than 15 minutes late.
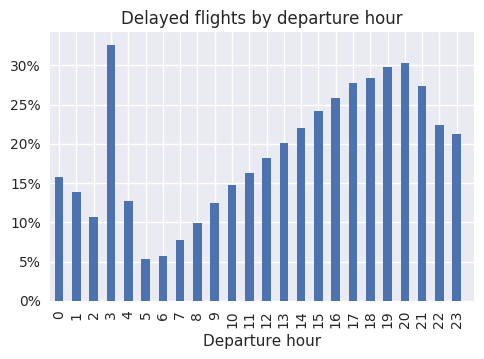
I sampled 100k flights from 2006 for the training set, and 100k flights from 2007 for the test set. Sadly, roughly 20% of flights were more than 15 minutes late, a fact that doesn't reflect well on the airline industry :D. It's easy to see how strongly departure time throughout the day correlates with the likelihood of delay:
I did not do any feature engineering, so the list of features is very basic:
Month
DayOfWeek
Distance
CRSDepTime
UniqueCarrier
Origin
Dest
I used the scikit-style wrapper for XGBoost, which makes training and
prediction from NumPy arrays a two-line affair (code). For TensorFlow, I used
tf.Experiment, tf.learn.runner, and the NumPy input functions to save some
boilerplate (code). TODO
Results
I started out with XGBoost and a decent guess at the hyperparameters, and immediately got an [AUC score](https://stats.stackexchange.com/questions/132777/what-does-auc-stand- for-and-what-is-it) I was happy with. When I tried the same settings on TensorFlow Boosted Trees, I didn't even have enough patience for the training to end!
While I kept num_trees=50 and learning_rate=0.1 for both models, I ended
up having to tweak the TF Boosted Trees examples_per_layer knob using an
hold-out set. It's likely that this is related to the novel layer-by-layer
learning algorithm featured in the TFBT paper, but I haven't dug in deeper. As
a starting point for comparison, I selected two values (1k and 5k) that
yielded similar training times and accuracy to XGBoost. Here's how the results
look like:
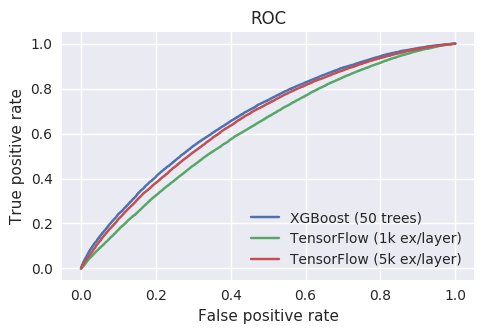
Accuracy numbers:
Model AUC score
-----------------------------------
XGBoost 67.6
TensorFlow (1k ex/layer) 62.1
TensorFlow (5k ex/layer) 66.1
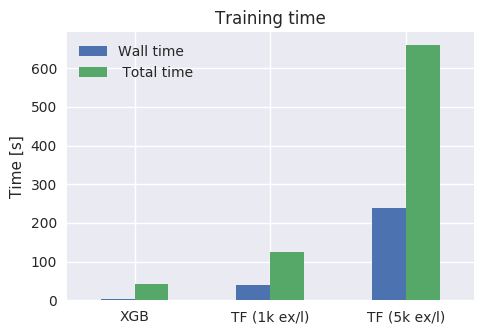
Training runtime:
./do_xgboost.py --num_trees=50
42.06s user 1.82s system 1727% cpu 2.540 total
./do_tensorflow.py --num_trees=50 --examples_per_layer=1000
124.12s user 27.50s system 374% cpu 40.456 total
./do_tensorflow.py --num_trees=50 --examples_per_layer=5000
659.74s user 188.80s system 356% cpu 3:58.30 total
Neither of the two settings shown for TensorFlow could match the training
time/accuracy of XGBoost. Besides the disadvantage in user time (total CPU
time used), it also seems that TensorFlow isn't very effective at
parallelizing on multiple cores either, leading to a massive gap in total
(i.e. wall) time too. XGBoost has no trouble loading 16 of the 32 cores in my
box (and can do better when using more trees), whereas TensorFlow uses less
than 4. I guess that the whole "distributed TF" toolbox could be used to make
TFBT scale better, but that seems overkill just to make full use of a single
server.
Conclusion
With a few hours of tweaking, I couldn't get TensorFlow's Boosted Trees implementation to match XGBoost's results, neither in training time nor accuracy. This immediately disqualifies it from many of the quick-n-dirty projects I would use XGBoost for. The limited parallelism of the implementation also means that it wouldn't scale up to big datasets either.
TensorFlow Boosted Trees might make sense within an infrastructure that's heavily invested in TensorFlow tooling already. TensorBoard and the data loading pipeline are two features that work fine on Boosted Trees too and could easily migrated from other Deep Learning projects based on TensorFlow. However, TF Boosted Trees won't be very useful in most cases until the implementation can match the performance of XGBoost (or I learn how to tune it).
To reproduce my results, get the training code on GitHub.