Short history of the Inception deep learning architecture
While looking for pretrained CNN models, I was starting to get confused about the different iterations of Google's Inception architecture. This short post recaps the two intense years of life of this (groundbreaking) model. I assume a pretty thorough understanding of the machinery of CNNs (a good resource for those concepts is here).
Network In Network, Lin et al. (2014)
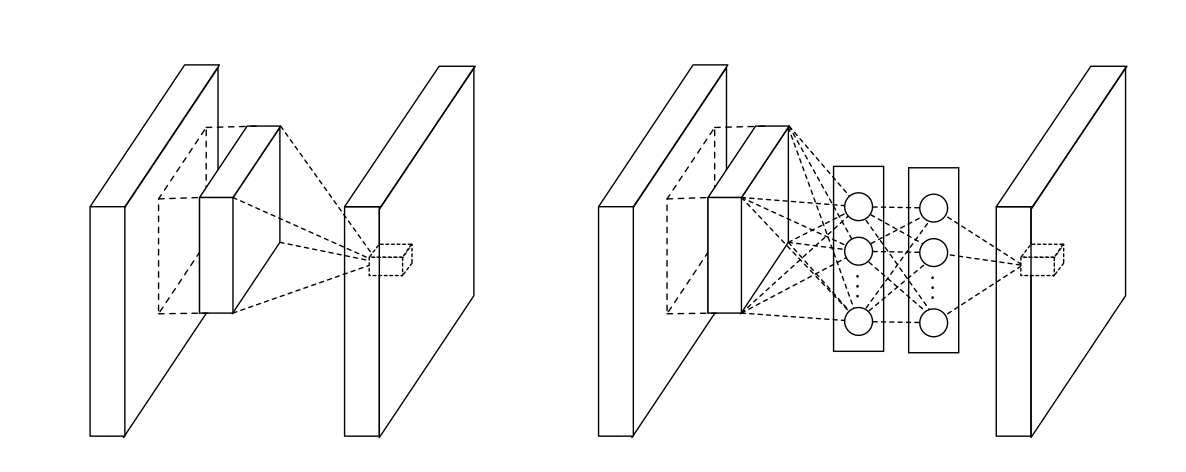
To the best of my knowledge, this paper really kicked off the whole "Inception" thing. The key insight was to realize that conventional convolutional "filters" can only learn linear functions of their inputs. Why not increase their learning abilities and abstraction power by having more complex "filters"? This paper gets rid of the linear convolutions that are the bread and butter of CNNs and instead connects convolutional layers through multi-layer perceptrons that can learn non-linear functions. Luckily, it turns out that these perceptrons are mathematically equivalent to 1x1 convolutions, and thus fit neatly within the CNN framework.
The second major achievement is that the increased abstraction power of these convolutional layers can lessen the need for fully connected (FC) layers at the top of the network. Instead, they spatially average the feature maps at the final layer, and directly feed these vectors to the softmax classifier. Getting rid of the FC layer cuts the number of parameters, and thus reduces the risk of overfitting and the computational load. The authors call this global average pooling and claim that it also improves robustness to spatial translation.
Going deeper with convolutions, Szegedy et al. (2014)
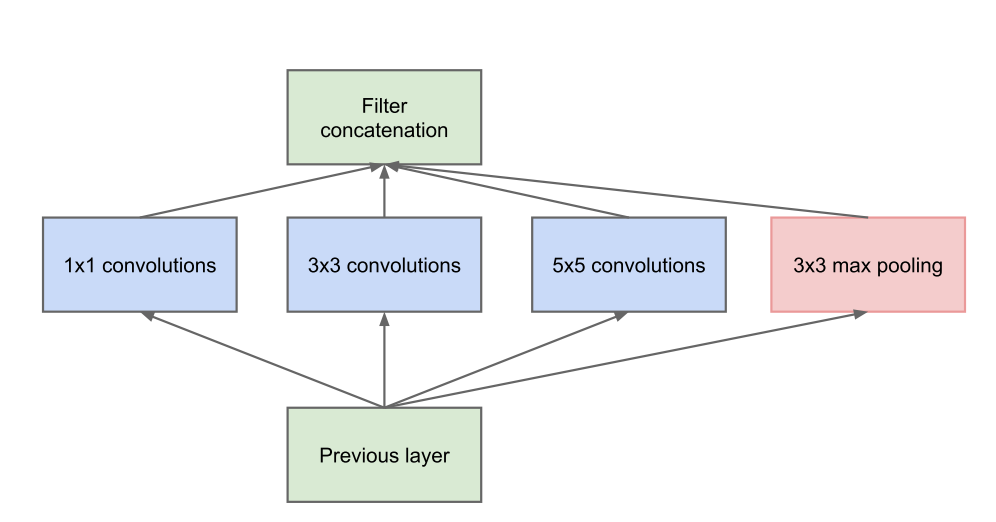
This paper introduces the Inception v1 architecture, implemented in the winning ILSVRC 2014 submission GoogLeNet. The main contribution with respect to Network in Network is the application to the deeper nets needed for image classification. From a theoretical point of view, Google's researchers observed that some sparsity would be beneficial to the network's performance, and implemented it using today's computing techniques.
To improve convergence on this relatively deep network, the authors also introduced additional losses tied to the classification error of intermediate layers. This trick is only used for training, and the output of these layers is discarded during inference.
Rethinking the inception architecture for computer vision, Szegedy et al. (2015)
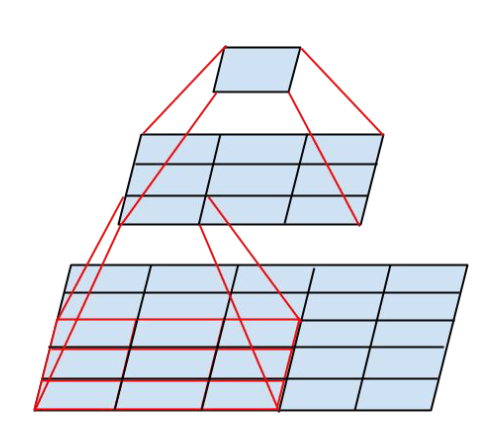
Authored by the same group of people as the original Inception, this work builds on the original and describes some decisions and tricks that led to its success. For example, the authors show how any convolution whose kernel is larger than 3x3 can be expressed more efficiently with a series of smaller convolutions. Even more, they suggest replacing large 7x7 filters with a pair of 1x7 and 7x1 convolutional layers.
The paper then goes through several iterations of the Inception v2 network that adopt the tricks discussed above (for example, factorization of convolutions and improved normalization).
By applying all these tricks on the same net, we finally get Inception v3, handily surpassing its ancestor GoogLeNet on the ImageNet benchmark.
v4: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, Szegedy et al. (2016)
This paper introduces Inception v4, a streamlined version of v3 with a more uniform architecture and better recognition performance. Also, the authors develop residual connection variants of both Inception architectures (Inception-ResNet v1 and v2) to speed up training.
Conclusion and pretrained models
After the initial breakthrough of the Inception architecture, most changes have been incremental. This means that any of these models would be good enough for initial work in new research areas outside of classification.
Inception-v3 pretrained weights are widely available, both in Keras and Tensorflow. I couldn't find weights for Inception v4, but there are a few implementations of the network already, so it's only a matter of time before someone burns through a few hundred of Kwh to train them.
Other resources
Some slides about using Inception-style architectures for scene classification and recognition.